|
|
 |
|
De z-toets. |
©
h.hofstede (h.hofstede@hogeland.nl) |
|
| |
|
Natuurlijk gaan alle beweringen
met getallen niet alleen over kansen of percentages.
Heel vaak wordt iets beweert over een gemiddelde. |
Neem bijvoorbeeld de jerrycan met motorolie hiernaast. Op het etiket
doet de fabrikant een bewering over een gemiddelde.
Zie je waar? (ga er
anders maar met de muis over).Tuurlijk: als er staat dat de
inhoud 4 liter is, dan betekent dat echt niet dat er in elke jerrycan
precies 4,0000000... liter olie zit. Zo nauwkeurig kan de fabrikant die
jerrycans echt niet vullen. Als de "vulmachine" afgesteld staat op 4
liter, dan zal de inhoud door wat willekeurige fluctuaties een beetje
rond die 4 liter schommelen.
Als die fluctuaties echt willekeurig zijn, dan beweert de fabrikant
eigenlijk dat de inhoud normaal verdeeld zal zijn met een gemiddelde van
4 liter. Hoe slordiger de vulmachine, des te groter zal de
standaarddeviatie zijn. |
 |
| |
|
| De bewering van de fabrikant zou
bijvoorbeeld de volgende kunnen zijn: |
| |
|
|
H0: de inhoud is
normaal verdeeld met
μ = 4 en
σ = 0,2 |
|
| |
|
Maar wat gebeurt er als een klant
een jerrycan koopt waar maar 3,9 liter blijkt in te zitten? Of 3,8 liter
of 3,7 liter?
Als de inhoud te veel afwijkt van het gemiddelde dan zal zo'n klant de
bewering H0 in twijfel trekken en beweren dat
m kleiner is dan 4. |
| |
|
|
|
| |
|
't Is eigenlijk precies zoals bij de p-toetsen,
met als enige verschil dat de figuur die bij de H0-bewering
hoort nu geen staafjesdiagram is, maar een klokvorm.
We zijn weer op zoek naar de grenswaarde G waarvoor de
overschrijdingskans (de rode oppervlakte) gelijk is aan het
significantieniveau (α, meestal 0,05)
|
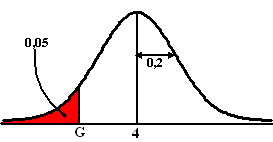 |
Als de meting aan de buitenkant
van de G-waarde terechtkomt wordt H0 verworpen, komt hij aan
de binnenkant terecht dan wordt H0 aangenomen.
In dit geval moet je om G te vinden oplossen: normalcdf(0,
G, 4, 0.2) = 0,05
Y1 = normalcdf(0, X, 4, 0.2) en Y2 = 0,05 en dan calc → intersect geeft grenswaarde G =
3,67
Dus pas bij een inhoud van minder dan 3,67 liter kun je (met 95%
betrouwbaarheid) stellen dat de machine op minder dan 4 liter staat
afgesteld. |
|
|
|
Nog twee puntjes om op te letten:
1. de continuïteitscorrectie.
Als je iets meet, en je doet alsof dat normaal verdeeld is, terwijl je
weet dat dat niet zo kan zijn omdat het om gehele getallen gaat, dan
moet je uiteraard weer de continuïteitscorrectie toepassen. Dat stond in
deze les voor
het geval je het niet meer weet. |
| |
|
2. tweezijdig toetsen.
Alles wat bij p-toetsen tweezijdig behandeld is, geldt nu gewoon
weer. Dus als H1 beweert
μ
≠ ..... dan moet je weer aan beide
kanten 1/2α
nemen in plaats van
α. |
| |
| |
|
|
OPGAVEN |
| |
|
| 1. |
Volgens een milieuactiviste is de
gemiddelde temperatuur in Nederland aan het stijgen.
Zij heeft gegevens uit de periode 1900-1980 waarin de gemiddelde
temperatuur gelijk was aan 9,2ºC met een standaarddeviatie van
0,3ºC.
Zij beweert dat de gemiddelde temperatuur in Nederland intussen
hoger is geworden. Als bewijs wijst zij op de gemiddelde
temperatuur in 2010, die gelijk was aan 9,6 ºC.
Mag zij daaruit inderdaad concluderen dat het gemiddelde hoger
is dan 9,2 ºC? Neem een significantieniveau van 5%. |
| |
|
|
| |
|
|
| 2. |
Een tuinder beweert trots dat de
lengte van zijn zonnebloemen normaal verdeeld is met een
gemiddelde van 2,4 meter en een standaarddeviatie van 40 cm.
Ik kies willekeurig één van zijn zonnebloemen en meet de lengte
daarvan.
Bij welke gemeten lengten zal ik (neem 10% significantieniveau)
mogen concluderen dat hij overdrijft? |
| |
|
|
| |
|
|
| 3. |
De gemiddelde bloeddruk (bovendruk)
van de Nederlanders is 130 (mg Hg) met een standaarddeviatie van
9,6.
Ik las in een rapport dat de gemiddelde bloeddruk van leraren
hoger is dan 130.
Nou ben ik zelf toevallig leraar, en dus heb ik meteen mijn
bloeddruk gemeten.
Die was 144.
Mag ik daaruit concluderen dat het rapport inderdaad klopt?
(neem
α = 0,05) |
| |
|
|
| |
|
|
|
| 4. |
De huismus komt over de hele wereld
voor.
Een bioloog in Europa heeft onderzocht dat het gewicht van de
huismus in Europa normaal verdeeld is met een gemiddelde van
29,2 gram en een standaarddeviatie van 1,8 gram.
Hij vraagt zich af of dat ook geldt voor huismussen in Amerika,
en vraagt daarom een Amerikaanse collega om het gewicht van een
willekeurige huismus daar te meten. Ze besluiten een
significantieniveau van 5% te nemen.Bij welke gewichten van
de Amerikaanse mus kunnen ze dan concluderen dat Amerikaanse
mussen een ander gewicht hebben dan Europese? |
| |
|
|
|
| |
|
|
| 5. |
Op het blik soepballetjes hiernaast staat "ca. 30
stuks".
Navraag blijkt dat Unox daarmee bedoelt dat het aantal
soepballetjes normaal verdeeld is met een gemiddelde van 30 en
een standaardafwijking van 1,0.
Ik koop een blik met daarin slechts 28 balletjes.
Mag ik naar aanleiding van deze miskoop met 5%
significantieniveau concluderen dat het gemiddeld aantal
balletjes in de Unox-blikken kleiner is dan 30? |
 |
| |
|
| |
|
| 6. |
Op een middelbare school is de tijd die
leerlingen per week spijbelen normaal verdeeld met een
gemiddelde van 50 minuten en een standaarddeviatie van 12
minuten. Dat vindt de schoolleiding onacceptabel hoog en men
besluit tot een strenger controlesysteem waarbij elk uur aan het
begin de conciërges alle klassen langsgaan om spijbelaars te
registreren.
Na een paar weken blijkt de gemiddelde spijbeltijd gelijk te
zijn aan 33 minuten.
Mag men met een significantieniveau van 5% vaststellen dat het
nieuwe controlesysteem geholpen heeft? |
| |
|
| |
|
| 7. |
examenvraagstuk VWO Wiskunde A, 1987.
In 1787 en 1788 schreven Alexander
Hamilton en James Madison de zogenaamde The Federalist Papers,
om de inwoners van New York te overreden de Constitutie te
ratificeren. Beide schrijvers ondertekenden met "Publius".
Van 48 van deze teksten is bekend dat zij van Hamilton zijn en van
50 dat zij van Madison zijn. Om ook van de overige teksten de
auteur te achterhalen, heeft men van diverse woorden geteld hoe vaak
ze in een tekst van Hamilton voorkomen en hoe vaak in een tekst van
Madison. Voor elk van die teksten heeft men daarna de frequentie per
1000 woorden berekend.
Van een woord weet men
dat dit bij Hamilton per 1000 woorden voorkomt met een gemiddelde
van 17,2 en een standaarddeviatie van 4,1. Men mag aannemen dat
de frequenties normaal verdeeld zijn.
Voor Madison zijn deze gegevens niet bekend.
Bij een gegeven tekst vindt men onder de eerste 1000 woorden dit
woord 24 maal. |
| |
|
|
|
| |
Onderzoek of
men bij een significantieniveau van 5% voldoende reden heeft te
twijfelen aan het auteurschap van Hamilton |
| |
|
|
|
| |
|
|
 |
|
©
h.hofstede (h.hofstede@hogeland.nl) |
| |
|
|
|
|