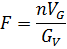|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Drie gemiddelden vergelijken. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| We bekijken de productie van drie machines die hetzelfde product produceren, maar waarvan de productiehoeveelheden wat schommelen (door allerlei onbekende redenen). Van elke machine wordt vijf keer een steekproef genomen en dat geeft de volgende tabel met resultaten. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Het
overall-gemiddelde van alle steekproeven is 52.2 De vraag is nu natuurlijk: zijn deze verschillen te wijten aan toevallige schommelingen of zijn de machines echt verschillend? Ofwel: komen die drie verschillende gemiddeldes door toevallige schommelingen of ligt er een verschillende μ aan ten grondslag? Laten we voorlopig een nulhypothese opstellen: H0: er is geen verschil: μA = μB = μC Als we de standaarddeviatie bekijken van de drie gemiddelde waardes uit de laatste kolom, dan vinden we σ = 3,93 Maar ja, die waarden van μ en σ zeggen niet alles, want de volgende tabel geeft precies dezelfde waarden: |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Ga zelf maar na dat
ook nu geldt
μ = 52,2 en σ = 3,93. Toch zijn de tabellen nogal verschillend, en dat zie je waarschijnlijk het best door een plaatje te maken: |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
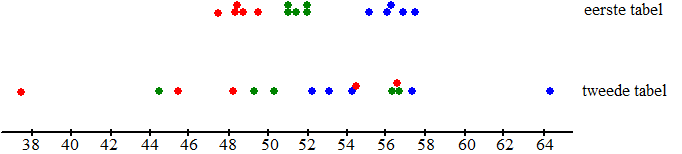
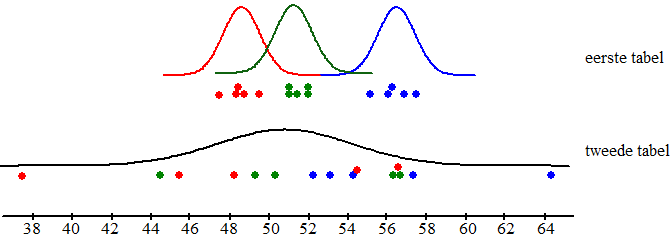
| De metingen uit de eerste tabel liggen duidelijk in drie "groepjes" per machine bij elkaar. De metingen in de tweede tabel zijn veel meer random verdeeld over de hele populatie. Het lijkt erop dat er dit aan de hand is: | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| De eerste tabel lijkt
afkomstig van drie verschillende machines met elk hun eigen
μ. In het tweede geval lijkt het er meer op dat er één grote
populatie is waarbij die verschillende kleuren willekeurige
schommelingen zijn. In het eerste geval zou ik daarom concluderen dat de
μ's verschillend zijn (dus H0 verwerpen). Onze nulhypothese was dat er géén onderliggende verschillende waarden van μ zijn: H0: μ1 = μ2 = μ3 Als drie metingen nemen we de gemiddelden van de machines: 48.6, 56.4, 51.6 uit de tabel. Die hebben gemiddelde waarde 52,2. De variantie van deze drie machine-gemiddelden is: σ2 = 1/(3 - 1) • {48.6 - 52.2)2 + (56.4 - 52.2)2 + (51.6 - 52.2)2 } = 15,48 Laten we ook de drie varianties van de meetwaarden per machine berekenen (uit de eerste tabel): σA2 = 1/(5 - 1) • {(48,4 - 48,60)2 + (49,7 - 48,60)2 + (48,7 - 48,60)2 + (48,5 - 48,60)2 + (47,7 - 48,60)2} = 0,52 σB2 = 1/(5 - 1) • {(56,1 - 56,40)2 + (56,3 - 56,40)2 + (56,9 - 56,40)2 + (57,6 - 56,40)2 + (55,1 - 56,40)2} = 0,87 σC2 = 1/(5 - 1) • {(56,7 - 51,68)2 + (51,5 - 51,68)2 + (51,5 - 51,68)2 + (52,1 - 51,68)2 + (51,5 - 51,68)2} = 0,22 Het gemiddelde van die drie varianties is 0,5367 (afgerond) We hebben nu twee gemiddelde varianties: de 15,48 en de 0,5367. • 15,48 = variantie van de drie gemiddeldes. Weet je wat? Vanaf nu noem ik hem VG • 0,5367 = gemiddelde van de drie varianties. Weet je wat? Vanaf nu noem ik hem GV Als je die eerste nou erg groot vindt vergeleken met de tweede dan zul je waarschijnlijk te maken hebben met het plaatje van de drie klokvormen van die eerste tabel. Als je ze ongeveer gelijk vindt zal je waarschijnlijk te maken hebben met het plaatje van die ene klokvorm van de tweede tabel. We berekenen daarom de "variantie-verhouding F": |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Als H0
klopt, dan heb je dus eigenlijk één grote populatie met variantie V waar
je willekeurig drie steekproeven uit neemt. Dan zal gelden F = 1, immers: • VG = V/n (weet je nog wel van vroeger: σG = σ/√n) dus nVG = V • het gemiddelde van die drie varianties (GV) zal ook ongeveer gelijk zijn aan V; ze zijn alle drie immers ongeveer V? Maar als H0 NIET waar is, dan geven de verschillende waarden van μ aanleiding tot extra spreiding en zal VG groot zijn vergeleken met GV. In die gevallen wordt F groter dan 1. Dus wordt onze F-toets:
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| In de twee tabellen
uit ons voorbeeld waren er 3 - 1 = 2 vrijheidsgraden in de noemer en 12
in de teller (immers elk van de drie metingen heeft 5 - 1 = 4
vrijheidsgraden). Dat geeft in de tabel een kritieke waarde F =
3,89. De eerste tabel leverde VG = 15,48 en GV = 0,5367 dus F = 3 • 15,43/0,5367 = 86,2 en dat is veel groter dan 3,89 dus kunnen we concluderen dat er wel een verschil is tussen de machines. De tweede tabel levert VG = 15,48 en GV = 35,75 (reken zelf maar na dat σA2 = 57,23, σB2 = 24,26 en σC2 = 25,76). Dus in het tweede geval is F = 3 • 15,43/35,75 = 1,29 en dat is kleiner dan 3,89 dus concluderen we dat er geen verschil is tussen de machines. Alles staat nog eens samengevat in het volgende ANOVA-schema (ANalysis Of VAriance) |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| De 15,43 wordt ook
wel de verklaarde variantie genoemd, want de verklaring
daarvan is het verschil in machines. De 0,5367 is de onverklaarde variantie: die komt door random fluctuaties in de metingen. Neem bijvoorbeeld de vierde meetwaarde van de tweede machine; die is 57,6. • Dat scheelt 57,6 - 52,2 = 5,4 van het gemiddelde van alle 15 meetwaarden. • De verklaarde afwijking is 56,4 - 52,2 = 4,2 (de afwijking van machine B t.o.v. het overall-gemiddelde) • De onverklaarde afwijking is 57,6 - 56,4 = 1,2 (de afwijking van deze meetwaarde t.o.v. het machine-gemiddelde) Samen geldt 5,4 = 4,2 + 1,2. Ik hoop dat je dat logisch vindt, want hier staat natuurlijk niets anders dan: |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Maar daaruit volgt dat, als je alle kwadratische afwijkingen in de tabel optelt, net zoiets geldt: | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Het bewijs daarvan staat hiernaast. |
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Hier staat dus
(totale kwadratische afwijking) = (verklaarde kwadratische afwijking) + (onverklaarde kwadratisch afwijking) Meteen maar even checken met onze tabel? (totale gemiddelde was 52,2) |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
• |
Totale kwadratische
afwijking: (48.4 - 52.2)2 + (49.7 - 52.2)2 + ... + (56,1 - 52.2)2 + 56.3 - 52.2)2 + ... + (52.1 - 52.2)2 + (51.1 - 52.2)2 + ... = 66,88 + 91,68 + 2,68 = 161,24 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
• |
Verklaarde
kwadratische afwijking: 5 • {(48,6 - 52.2)2 + (56.4 - 52.2)2 + (51.6 - 52.2)2 } = 154,8 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
• |
Onverklaarde
kwadratische afwijking: (48.4 - 48.6)2 + (49.7 - 48.6)2 + ... + (56.1 - 56.4)2 + (56.3 - 56.4)2 + ... + (52.1 - 51.6)2 + (51.1 - 51.6)2 + ... = 2,08 + 3,48 + 0,88 = 6,44 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Check:
161,24 = 154,8 + 6,44 klopt inderdaad. Je zou het ANOVA-schema dan ook zó kunnen opstellen: |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
© h.hofstede (h.hofstede@hogeland.nl) |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||