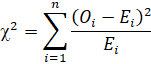|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| De χ-kwadraat verdeling. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| De
χ2 verdeling (spreek uit "chi-kwadraat") is
één van de meest gebruikte en misbruikte verdelingen in de statistiek.
Waarschijnlijk komt dat omdat deze verdeling makkelijk en op meerdere
gebieden toe te passen is. Officieel is de χ2 verdeling gedefinieerd als: |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Ofwel simpeler gezegd: "Als
variabelen normaal verdeeld zijn, dan zijn hun kwadraten
χ2-verdeeld". We zullen de komende lessen een aantal verschillende toepassingen van de χ2 verdeling zien: |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Zoals je ziet: een echt
manusje van alles! De kwaliteit van een fit. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Bij een onderzoek naar
obesitas (zwaar overgewicht) onder de jeugd werden er 400 kinderen
bekeken en daarbij werden er 124 gevallen van obesitas gevonden. Dat is
maar liefst 31%. De volgende tabel geeft de aantallen voor vier leeftijdscategorieën: |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| We vragen ons af of obesitas in
alle leeftijdsgroepen even vaak voorkomt, en stellen als nulhypothese: H0: "Obesitas komt bij alle leeftijden even vaak voor". Hoe goed passen de gegevens uit deze tabel bij deze hypothese? Ofwel: hoe goed "fit" deze tabel met H0? We breiden de tabel daarvoor uit met de verwachte aantallen obesitas (E van "Expected", en het gemeten aantal is de O van "Observed") als de kans inderdaad voor elke groep 31% is: |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Daarna berekenen we de kwadratische afwijkingen tussen O en E, en delen die door de verwachte aantallen E (om er een wegingsfactor aan te geven): | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
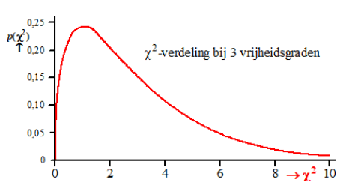
| De som van de laatste kolom geeft nu de waarde van χ2 bij 3 vrijheidsgraden. Het aantal vrijheidsgraden is altijd één minder dan het aantal metingen, omdat de metingen niet onafhankelijk zijn. De laatste waarde 1,17 bijvoorbeeld ligt al vast als de andere drie bekend zijn, omdat het totaal vast ligt. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| (De O staat voor "observed" en de
E voor "expected"). Tot slot kijken we hoe groot de kans op een minstens even grote χ2 is. De χ2-verdeling voor 3 vrijheidsgraden zie je hieronder: |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
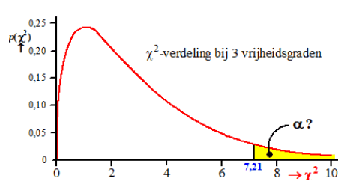
| En nu is het de vraag of de overschrijdingskans (dat is de kans op een minstens even grote waarde van χ2) kleiner is dan het significantieniveau α. Ofwel: Als α = 0,05, is de gele oppervlakte hieronder dan meer of minder dan 5%? | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Er zijn uiteraard weer tabellen
om bij allerlei verschillende vrijheidsgraden en significantieniveaus de
grenswaarden op te zoeken. De grenswaarde bij 3 vrijheidsgraden en
α = 0,05 is gelijk aan 7,81. De
gele oppervlakte is kennelijk groter dan 0,05 dus we moeten concluderen
dat er geen reden genoeg is om H0 te verwerpen. Hier is de tabel met de grenswaarden voor de χ2-verdelingen. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Als je het graag exact wilt weten, dan heb je hier de formule voor de kansdichtheid van de chi-kwadraat verdelingen met k vrijheidsgraden: | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Daarin is Γ de beroemde gammafunctie waarover je in deze les meer te weten kunt komen. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
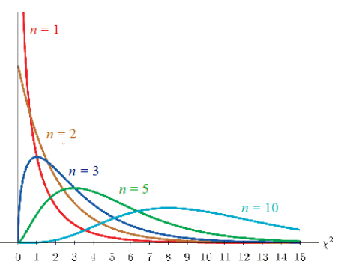
| Je hebt er verder niets aan, maar hieronder staan de grafieken van de verschillende χ2-verdelingen. Nou ja.... kun je je er misschien een beetje iets bij voorstellen..... | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Een binomiale toets benaderen. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Een onderzoeker wil
kijken of snoepproducten die bij de kassa aangeboden vaker worden
verkocht worden dan snoepproducten ergens anders in de winkel. Hij zet
daarom twee identieke displays met snoep in de winkel: eentje bij
de kassa en eentje ergens anders. Het blijkt dat op de eerste dag 41 snoepproducten uit het kassadisplay zijn verkocht en 27 uit het andere display. Mag je concluderen dat de kassadisplay beter verkoopt (met α = 0,05)? Je kunt dit makkelijk met een p-toets berekenen. Dat gaat als volgt: H0: "Er is geen verschil": p = 0,5 (voor elke klant die snoep kocht was de kans voor beide displays 50%) H1: "Er is wél een verschil": p ≠ 0,5 (succes = een snoepzakje uit de kassadisplay verkocht). n = 68. Meting was 41 successen. P(X ≥ 41) = 1 - binomcdf(68, 0.50, 40) = 0,0571 Dat is groter dan 0,5α (= 0,025) dus H0 aannemen: de kassadisplay verkoopt niet significant beter. We kunnen dit ook benaderen met een χ2-verdeling. Omdat er maar twee metingen zijn (kassadisplay en andere display) is het aantal vrijheidsgraden 2 - 1 = 1. Maar omdat de binomiale verdeling discreet is (succes/geen succes), en de χ2-verdeling continu is, is er ook hier een continuïteitscorrectie nodig (net zoals bij de normale benadering van de binomiale verdeling). Die correctie houdt in dit geval in dat de gemeten frequenties 0,5 dichter naar de verwachte frequenties moeten worden genomen. Dat geeft deze tabel voor de χ2-verdeling: |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| χ2 = 1,24
+ 1,24 = 2,48 De tabel geeft bij 1 vrijheidsgraad en α = 0,05 een kritieke waarde van 3,84 De gemeten χ2 is kleiner dan de kritieke waarde, dus H0 wordt aangenomen: er is niet voldoende verschil om te kunnen concluderen dat de kassadisplay beter verkoopt.
één- of tweezijdig? |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| De kritieke waarde voor ons voorbeeld is nu 2,71. Nog steeds H0 aannemen. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
© h.hofstede (h.hofstede@hogeland.nl) |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||