|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Een bijkomend
probleem bij het interpreteren van de correlatiecoëfficiënt is de vraag
of een twee keer zo grote r ook een twee keer zo goede correlatie
betekent. Dat is niet zo! Om dat te bekijken gaan we twee variaties bekijken: Variatie 1: Schommeling rond het gemiddelde Als er helemaal geen verband zou bestaan tussen x en y dan zouden alle y-waarden zomaar wat lukraak schommelen rond hun gemiddelde. Dit getal geeft dus aan hoeveel de punten in y-richting schommelen rond hun gemiddelde. Variatie 2: Residuen. Mét het regressiemodel is de som van de variatie van alle punten t.o.v. de regressielijn natuurlijk gelijk aan de som van de residuen. Dat zal een kleiner getal zijn dan die totale variatie rond het gemiddelde hierboven, omdat we immers het kwadraat van al die residuen hebben geminimaliseerd toen we regressielijn opstelden. Het verschil tussen deze beide variaties is het deel van de totale variatie dat door het regressiemodel wordt verklaard. Kijk maar naar dit kleine getallenvoorbeeldje met een puntenwolk van vier punten. De regressielijn hiervan was de lijn y = 0,2x + 2,5 en het centrale punt is (2.5, 3) |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Van de totale variatie van 2 wordt 0,2 door het regressiemodel verlaagd, en 1,8 blijft over (nog steeds ook in het regressiemodel een afwijking). We definiëren nu de determinatiecoëfficiënt R² als het deel van de totale variatie dat door het regressiemodel wordt verminderd: | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| In ons getallenvoorbeeld is R² = 0,2/2 = 0,10. Dat is niet bijster goed; slechts 10% van de variaties van de y-waarden wordt weggewerkt door het regressiemodel. In formule zou R² er dan natuurlijk zó uitzien: | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
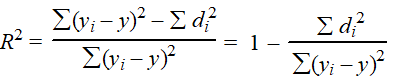 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| En het mooie van deze R²
is dat hij voor élk model geldt, niet alleen het lineaire! Bij de
afleiding is nergens gebruikt dat de regressielijn lineair moet zijn. Die R² heet trouwens niet voor niets R²...... De letter R is weer gebruikt omdat bij lineaire regressie R² gelijk is aan onze ouwe bekende r² (die R² heet ook wel de lineaire determinatiecoëfficiënt). Het bewijs daarvan staat hiernaast. |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Met deze R2 kun je bijvoorbeeld ook onderzoeken welk model nou het best past bij een puntenwolk. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Andere regressiemodellen. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
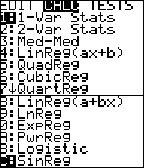
| Als je om de één of
andere reden vermoedt dat een rechte lijn niet het best bij jouw
puntenwolk past, dan kun je met de GR ook andere regressiemodellen
toepassen. Je vindt ze allemaal onder STAT - CALC - Hiernaast zie je de hele lijst. We zullen de belangrijksten bespreken, maar dat doen we in twee groepen. |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Groep 1. 4: LinReg (ax + b) 9: LnReg (a + b • lnx) 0: ExpReg (a • bx) A: PwrReg (a • xb) |
Groep 2. 5: QuadReg (ax2 + bx + c) 6: CubicReg (ax3 + bx2 + cx + d) 7: QuartReg (ax4 + bx3 + cx2 + dx + e) B: Logistic( c/(1 + a • ebx) ) C: SinReg (a • sin(bx + c) + d) |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Tussen haakjes staat steeds wat
voort soort formule je GR bij deze lijsten verzint. Zie je de overeenkomsten en de verschillen tussen deze twee groepen? Het zit hem erin, dat in groep 1 in al die formules TWEE constanten a en b staan, en bij de formules uit groep 2 méér constanten. De formules uit groep 1 zijn in wezen lineaire regressie formules. Als je lijst L1 voor x hebt en lijst L2 voor y, en je wilt de formule y = a + b • lnx opstellen, dan kun je die lijst met x-waarden vervangen door een nieuwe lijst L3 met daarin X = lnx. Immers dan geldt y = a + b • X en kun je gewoon lineaire regressie tussen L3 en L2 toepassen. Zo kun je y = a • bx schrijven als lny = lna + xlnb, dus als je neemt Y = lny dan staat daar Y = A + x • B en kun je weer met lineaire regressie A (lna) en B (lnb) berekenen. Tenslotte bij y = a • xb staat er lny = lna + blnx dus dan neem je de nieuwe lijsten Y = lny en X = lnx en dan staat er Y = A + b • X. Lineaire regressie levert je A (lna) en b. In al deze gevallen vind je dus een lineaire correlatiecoëfficiënt r en een lineaire determinatiecoëfficiënt R² . |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Bij groep 2 is dat anders. Daar staan meer constanten in de formules. De regressie is niet meer lineair, en je kunt het niet meer hebben over de correlatiecoëfficiënt r. Alleen de determinatiecoëfficiënt R² bestaat nog wel, en geeft aan hoe goed het model past bij de puntenwolk. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Welk model kiezen we? | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Tja, dat is lastig. Wiskundigen vinden een eenvoudiger model in principe ook mooier, dus zullen al gauw kiezen voor een model uit groep 1. Hoe meer constanten in de formule, hoe "lelijker" het model. Maar ja, we willen ook graag een R² die zo dicht mogelijk bij 1 ligt. Meestal "proberen" we een paar modellen, en alleen als modellen met meer constanten een spectaculaire verbetering van R² geven zullen we daarvoor kiezen. voorbeeld. |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
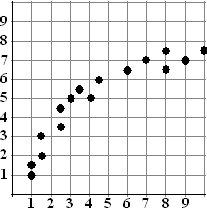
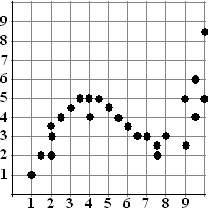
| Neem de volgende tabel met punten en de bijbehorende puntenwolk ernaast. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
 |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
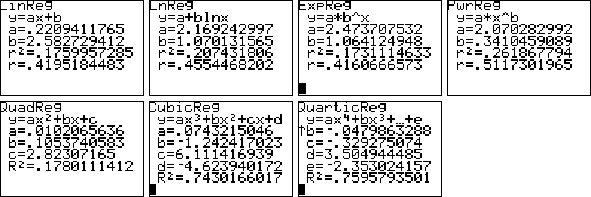
| Hieronder staan zeven modellen die we hebben geprobeerd: | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Als we voor het simpelste model
zouden kiezen (eentje uit de bovenste rij: groep 1) dan zouden we kiezen
voor PwrReg met r² = 0,26. In de onderste rij
geeft echter CubicReg een spectaculaire verbetering naar R² =
0,74. QuarticReg is nóg ietsje beter, maar niet erg veel, en het is wél een hele constante extra. |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
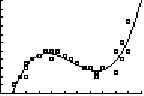
| De keuze valt daarom
waarschijnlijk op CubicReg: y = 0,07x3 - 1,24x2 + 6,11x - 4,62 Hiernaast zie je hoe geweldig goed die past bij de puntenwolk! |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| OPGAVEN | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
© h.hofstede (h.hofstede@hogeland.nl) |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||