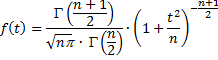|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| De t-verdeling. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Bij het nemen van een
steekproef gingen we in de vorige les steeds uit van een normale
verdeling in een hele populatie. We vonden dan een bepaald gemiddelde in onze steekproef en probeerden daar conclusies uit te trekken over het gemiddelde in de hele populatie. Dat werden dan betrouwbaarheidsintervallen. Bij de berekeningen van die betrouwbaarheidsintervallen hadden we de standaarddeviatie (σ) nodig. Maar een erg zwak punt in het verhaal daarbij is, dat we die standaarddeviatie van de hele populatie helemaal niet kennen! (Die kun je alleen vinden door de hele populatie te meten, en tja, dan is het geen statistiek meer..... dan is het gewoon de absolute waarheid....Bah! Stel je voor zeg!!) We namen dan uit nood maar gewoon de standaarddeviatie van onze steekproef, en maakten de aanname (hoop?) dat de standaarddeviatie van de hele populatie daar wel gelijk aan zou zijn. Die aanname klopt natuurlijk niet! |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
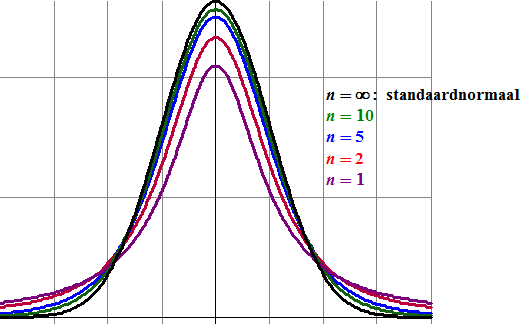
| Ik hoop dat je aanvoelt dat de standaarddeviatie van je steekproef groter zal zijn dan de standaarddeviatie van de hele populatie. Het betekent dat de z = (X - μ)/σ van de standaardnormale verdeling nu verandert in t = (X - μ)/s waarbij die s de standaarddeviatie van je steekproef is. Maar die s hangt wel af van de steekproefgrootte n, dus dat betekent dat je voor elke steekproefgrootte n een andere verdeling voor t krijgt. Die verdelingen zijn niet meer gelijk aan een standaardnormale verdeling alhoewel ze er wel op lijken. Hieronder zie je een aantal zulke t-verdelingen. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Zoals je ziet zijn de
staarten van de verdeling wat groter dan bij de normale verdeling, en
dat is maar goed ook: bij een kleinere steekproef verwachten we
natuurlijk een grotere kans op uitschieters. Voor n steeds groter
nadert de t-verdeling de standaardnormale verdeling (de zwarte
hierboven) Je ziet dat dat trouwens best snel gebeurt: vanaf n
= 50 is de t-verdeling haast niet meer te onderscheiden van
de standaardnormale verdeling. De formule van de t-verdeling is er eentje om niet al te lang te onthouden: |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Die
Γ is de gammafunctie, en je ziet dat er inderdaad een n als
parameter in voorkomt. Voor elke n een andere t-verdeling.
(In veel statistiekboeken zie je trouwens dat in plaats van n
wordt gewerkt met df = n - 1, waarin df staat
voor "degrees of freedom": het aantal vrijheidsgraden) Ik ken eigenlijk weinig wiskundigen die deze formule actief gebruiken (hoogstens misschien om anderen mee te imponeren). Iedereen gebruikt eigenlijk alleen maar de tabellen voor de t-waarden die bij allerlei n aangeven waar de oppervlakte 10%, 5%, 1% enz. is. Die heb je immers nodig om de betrouwbaarheidsintervallen te berekenen. Hier is 'íe: |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Die laatste rij geeft
dus de z-waarden van de standaardnormale verdeling. Voorbeeld Ik heb een mini-onderzoekje gedaan onder 10 kinderen van groep 8, waarin ik ze heb laten bijhouden hoeveel minuten ze per dag achter de computer zaten. Dat leverde op: 125 - 58 - 15 - 235 - 156 - 88 - 166 - 210 - 142 - 52 Dat geeft een gemiddelde van 90,7 met een standaarddeviatie van 66,45 Dus voor het gemiddelde van 10 metingen is σ = 66,45/√10 = 21,01 Ik wil graag een 95%-betrouwbaarheidsinterval voor het gemiddelde van alle groep-8 kinderen in Nederland opstellen. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| • | Met de
standaardnormale verdeling zou ik vinden z =
±1,960 dus
μ = 90,7 ± 1,96 • 21,01 Het 95%-betrouwbaarheidsinterval wordt [58.5, 132.9] |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| • | Met de t-verdeling
voor n = 10 vind ik t = ±2,262
dus
μ = 90,7 ± 2,262 • 21,01 Het 95%-betrouwbaarheidsinterval wordt [43.2, 138.2] |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Je ziet: het scheelt nogal. Die laatste is uiteraard de goede. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Als de steekproefgrootte toeneemt wordt de nauwkeurigheid groter (de breedte van het betrouwbaarheidsinterval dus kleiner), en dat is dus vanwege twee redenen: | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 1. | de standaarddeviatie wordt gedeeld door √n | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 2. | de kritieke waarde voor t wordt kleiner als n groter wordt. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| OPGAVEN | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 1. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
© h.hofstede (h.hofstede@hogeland.nl) |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||