|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Voorspellingen. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Als we aan de hand van een puntenwolk een
regressielijn van x op y hebben opgesteld, dan kunnen we
die lijn natuurlijk gebruiken om van nieuwe x-waarden de
bijbehorende y te voorspellen. (We zagen al eerder dat het
regressie-effect er daarbij voor zorgt dat extremen waarden een
voorspelling opleveren die "meer naar het gemiddelde" toe ligt.). De vraag is nu eigenlijk:
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Het zal je hopelijk intussen duidelijk zijn dat bij hoge (positieve of negatieve) correlatie, de voorspellingen betrouwbaar zijn, en bij lage correlatie onbetrouwbaar. Bij hoge correlatie liggen de gemeten punten bijna op een rechte lijn, en zal de voorspelling daar waarschijnlijk ook weinig van afwijken. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
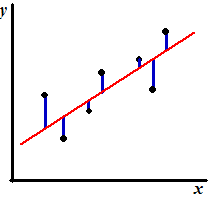
Maar hoe goed is nou zo'n voorspelling? Hóe hangt de nauwkeurigheid van r af? Welke afwijkingen van de voorspelling zijn te verwachten? Allemaal vragen waarvan het antwoord in de residuen di terug is te vinden. Dat waren die blauwe afwijkinkjes in de figuur hiernaast. Als die groot zijn, is de voorspelling onnauwkeurig, als ze klein zijn nauwkeurig. Daarom wordt als maat voor de betrouwbaarheid van de voorspelling de standaardafwijking van deze residuen genomen. Die geeft immers goed de spreiding van de residuen aan. |
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Die schattingsfout noemen we
σd (de standaardafwijking
van de residuen). Die is gelukkig erg makkelijk te berekenen: d = y - (ax + b) = y - ax - b dus d + ax + b = y Om de standaarddeviatie te berekenen moet je de kwadraten van de afzonderlijke standaarddeviaties optellen: σd2 + σax2 + σb2 = σy2 Maar omdat a en b constanten zijn is σax = a× σx en is σb = 0 Dus σd2 + a2 × σx2 = σy2 ofwel σd2 = σy2 - a2 × σx2 Als je dat combineert met de eerder gevonden vergelijking a = r × σy/σx dan geeft dat: |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
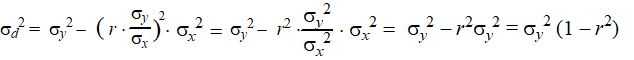 |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| en daaruit volgt dan eenvoudig: | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Kortom de gevonden voorspelde
waarde is normaal verdeeld met als gemiddelde de y-waarde
op de regressielijn, en als standaarddeviatie
σd.
(dit alles nog onder de stilzwijgende aannames dat de residuen
"willekeurig" ofwel "normaal verdeeld" zijn, hieronder gaan we
daar dieper op in....). Als dat zo is, dan kunnen we met de normale verdeling wel weer uitrekenen hoe groot de kans is dat de werkelijke waarde tussen bepaalde grenzen zal liggen. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Scedasticiteit. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Ik heb, om eerlijk te zijn, bij
de afleiding van de formule voor
σd
stiekem iets verzwegen...... Het zit hem in die regel waar ik voor de berekening van s, de kwadraten optelde: σd2 + σax2 + σb2 = σy2 Maar dat geldt alleen als de variabelen onafhankelijk van elkaar zijn!!!!! Dus dat gaat ervan uit dat σd voor elke x hetzelfde is. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Het gaat er eigenlijk van uit dat de y-waarden bij een bepaalde x elke keer normaal verdeeld zijn met dezelfde standaarddeviatie. Zoiets als in de figuur hiernaast..... Die mini-klokvormpjes geven de verdeling van alle y-waarden bij een bepaalde x aan. Scedasticiteit betekent "verspreiding" en we noemen een puntenwolk homoscedastisch als de spreiding in de y-waarden overal gelijk is (dan hebben alle klokvormpjes hiernaast dezelfde standaarddeviatie). Als dat niet het geval is, heet zo'n puntenwolk heteroscedastisch, en in dat geval mag je de formule voor σd hierboven NIET gebruiken! |
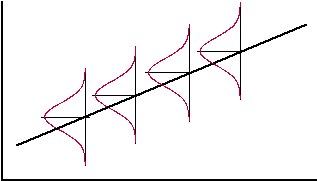 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
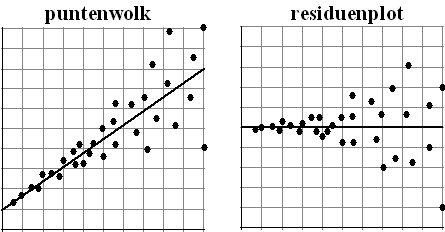
| Het komt regelmatig voor dat de
residuen steeds groter worden als x groter worden. Of juist
steeds kleiner. Je ziet dat effect het duidelijkst aan de residuplot.
Als de residuen naar één kant toe steeds groter worden dan is er iets
verdachts aan de hand... Hieronder zie je zo'n puntenwolk met bijbehorende residuplot. Aan beiden is eigenlijk wel te zien dat deze puntenwolk heteroscedastisch is. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Het waaiert naar rechts toe uit, dus dat betekent dat σd groter wordt als x groter wordt. Hier zul je zeker de bovenstaande formule voor σd niet mogen gebruiken, en kun je daarom weinig zeggen over de betrouwbaarheid van de voorspelling. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Normaal verdeeld? | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Als de residuen inderdaad
"willekeurig" zijn, dan zullen ze normaal verdeeld moeten zijn (met
uiteraard gemiddelde
μ = 0). Als dat
niet zo is, dan kun je hun standaarddeviatie
σd
wel uitrekenen, maar daar kun je vervolgens niets mee. Neem bijvoorbeeld de puntenwolk hieronder. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
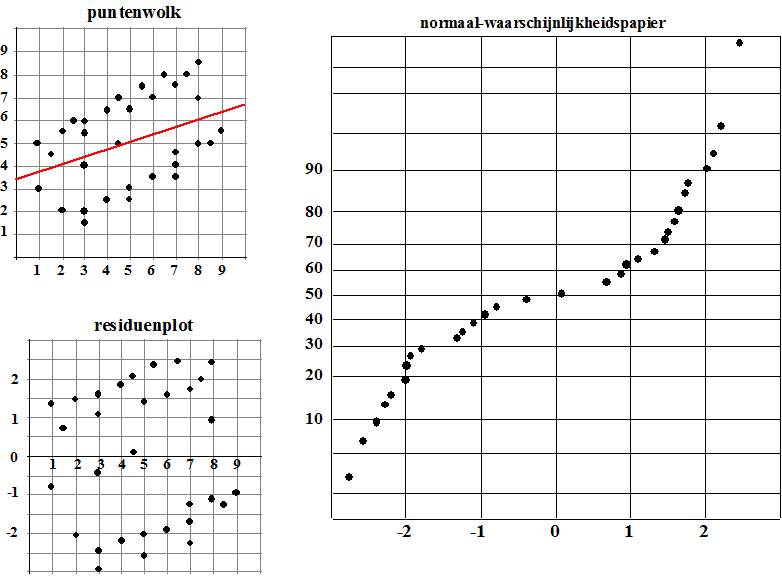
| Linksboven zie je de puntenwolk met de regressielijn y = 0,35x + 3,33 en correlatiecoëfficiënt r = 0,4. Linksonder staat de bijbehorende residuplot. Maar als je die residuen op normaal waarschijnlijkheidspapier tekent, dan komt daar helemaal geen rechte lijn uit. De residuen zijn dus absoluut niet normaal verdeeld! Residuen zo rond de 0 komen haast niet voor, en tussen de 1 en 2,5 en tussen de -1 en -2,5 juist erg vaak. Het lijkt erop dat we hier te maken hebben met twee aparte populaties | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
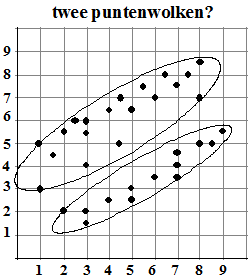
| Als je bijvoorbeeld van de beide "deelpuntenwolken"
hiernaast de correlatiecoëfficiënten uitrekent vind je r = 0,87 voor de
bovenste wolk en voor de onderste r = 0,96. |
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| OPGAVEN | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
© h.hofstede (h.hofstede@hogeland.nl) |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||