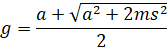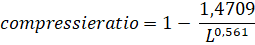| UITWERKING |
| |
|
| Het officiële (maar
soms beknoptere) correctievoorschrift kun je
HIER
vinden. Vooral handig voor de onderverdeling van de punten. |
| |
|
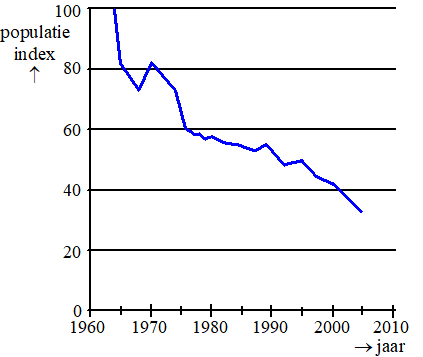
| 1. |
aflezen uit de grafiek: in 2005 was het indexcijfer ongeveer 33.
indexcijfer 100 hoort bij 126000 grutto's
verhoudingstabel: |
| |
|
| |
?? =
33 • 126000/100 = 41580
afgerond op duizendtallen is dat 42000. |
| |
|
| 2. |
de
grenswaarde voor uitsterven is g = 1.
1 = (0,81 + √(0,6561 + 1,3122m)/2
2 = 0,81 + √(0,6561 + 1,3122m
1,19 = √(0,6561 + 1,3122m)
1,4161 = 0,6561 + 1,3122m
0,76 = 1,3122m
m = 0,5791...
afgerond m
= 0,58 |
| |
|
| 3. |
m
= 2 en g = 1 geeft 1 = (a + √(a²
+ 4s²))/2
Door a en s klein genoeg te nemen moet je onder de 1
kunnen komen.
bijv. a = 0,01 en s = 0,01 geeft g
= 0,016
zulke waarden van a en s bestaan dus WEL. |
| |
|
| 4. |
s = √(2
-
2a) = (2 - 2a)0,5
s ' = 0,5(2 - 2a)-0,5 • -2
s ' = -1/√(2 - 2a)
omdat die wortel altijd een positief getal is, is s' altijd
negatief.
dus de grafiek daalt, dus een toename van a geeft een afname van
s
de bewering is juist. |
| |
|
| 5. |
bij 8
rondes van 4 spellen speelt elk paar 32 spellen
bij 192 paren zijn dat 32 • 192 = 6144 spellen
maar nu is elk spel dubbel geteld (want aan een spel doen 2 paren mee)
dus er zijn 6144/2 =
3072 spellen gespeeld. |
| |
|
| 6. |
op
elke locatie spelen 192/16 = 12 paren.
behalve het paar
Hendriks-Hendriks spelen er dus nog 11 andere paren op deze locatie.
In totaal zijn er 191 andere paren.
De kans dat Van Zomeren-Zenderink ook op deze locatie speelt is dus
11/191 |
| |
|
| 7. |
De
kans dat een willekeurig paar een hogere score haalt is P( X
> 54,66 met
μ = 50,00 en
σ =
7,12)
P(X > 54,66) = 1 - P(X < 54,66) = 1 - normalcdf(0, 54.66, 50.00, 7.12) =
0,2564
Dus naar verwachting zullen er 0,2564 • 192 = 49,2... paren hoger
eindigen
De verwachte positie is dus plaats 50. |
| |
|
| 8. |
μ
+ 2σ
= 49,93 + 2 • 7,07 = 64,07
μ
- 2σ
= 49,93 - 2 • 7,07 = 35,79
en de tabel vallen de nummers 1 tm 4 en 186 tm 190 daarbuiten
Dat zijn er 4 + 5 = 9 en dat is 9/190
• 100% = 4,7%
Dus ertussen valt 95,3% en dat klopt aardig met regel 2.
de mediaan is nummer (190 + 1)/2 = 95,5
dus tussen de nummers 95 en 96
Dat is (50,35 + 50,34)/2 = 50,345
dat is niet gelijk aan het gemiddelde (49,93) dus aan de derde regel is
niet voldaan. |
| |
|
| 9. |
H0:
p(60 punten of meer) = 0,80
H1: p < 0,80
meting is 10 van de 16
overschrijdingskans = P(X ≤ 10) = binomcdf(16, 0.80, 10) = 0,082
dat is groter dan 0,05 dus er is NIET voldoende reden om de toeschouwer
gelijk te geven (H0 aannemen). |
| |
|
| 10. |
de
kans dat een willekeurig persoon Mandarijn spreekt is 800/6800
= 0,1176
omdat de wereldbevolking nogal groot is mag je dit beschouwen als een
experiment met terugleggen, dus binomiaal.
n = 6, p = 0,1176
P(minstens één) = 1 - P(geen) = 1 - binomcdf(6, 0.1176, 0) =
0,528
dat is inderdaad meer dan 50%
OF
P(mandarijn) = 0,1176 dus P(geen mandarijn) = 0,8824
P(6 keer niet) = 0,88246 = 0,4720
P(minstens één wel) = 1 - 0,4720 = 0,528 |
| |
|
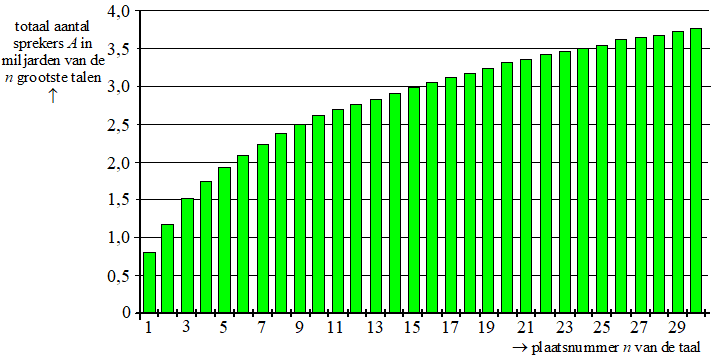
| 11. |
de eerste 15 talen hebben samen 2974 miljoen sprekers.
nrs. 16 tm 44 hebben tussen de 70 miljoen en 20 miljoen
sprekers
dat zijn 29 talen, met in totaal tussen de 29 • 70 = 2030 miljoen en 29
• 20 = 580 miljoen sprekers.
nrs. 45 tot en met 86 hebben elk minstens 10 miljoen en hoogstens 20
miljoen sprekers.
Dat zijn 42 talen met in totaal tussen de 42 • 10 = 420 miljoen en 42 •
20 = 840 miljoen sprekers.
meer dan 10 miljoen ligt tussen de 2974 + 580 + 420 = 3974 miljoen
sprekers en 2974 + 2030 + 840 = 5844 miljoen sprekers.
5,7 miljard is 5700 miljoen, dus dat is inderdaad mogelijk. |
| |
|
| 12. |
er
komt van een nummer naar het volgende steeds iets bij dus de grafiek
stijgt.
omdat de talen op volorde van klein naar groot staan wordt de
hoeveelheid die erbij komt steeds kleiner, dus de grafiek is afnemend
stijgend. |
| |
|
| 13. |
A =
0,92 • n0,43
A' = 0,43 • 0,92 • n-0,57 = 0,3956/n0,57
de
afgeleide is altijd positief, dus de grafiek van A is stijgend.
als n
groter wordt, dan wordt n0,57 ook groter dus dan wordt
van de afgeleide de noemer groter.
dan wordt de afgeleide zelf kleiner
dus wordt de stijging van A kleiner als n groter wordt. |
| |
|
| 14. |
A =
0,92 • n0,43 |
| |
1/0,92
A = n0,43
1,08...•A = n0,43
n = (1,08... • A)1/0,43
n = 1,08...1/0,43 • A1/0,43
n = 1,08...2,32... • A2,33
n = 1,21 • A2,33
dus b = 1,21
en c = 2,33 |
| |
|
| 15. |
A =
6,8(1 -
gn)
n = 15 geeft A = 2974
2,974 = 6,8(1 - g15)
0,437... = 1 - g15
g15 = 0,562...
g = 0,562...1/15 =
0,96 |
| |
|
| 16. |
Hij
reed 30 km met 80 km/uur en 30 km met 90 km/uur
30 km met 80 km/uur kost 30/80 uur
30 km met 90 km/uur kost 30/90 uur
In totaal kostte het rijden dus 30/80 +
30/90 = 0,7083... uur
De afstand was 60 km, dus de snelheid gemiddeld 60/0,7083...
= 84,7 km/uur. |
| |
|
| 17. |
lijn
door (80, 21.62) en (110, 15.95)
a = (15.95 - 21.62)/(110 - 80) = -0,189
L = -0,189v + b
21.62 = -0,189 • 80 + b geeft b = 36,74
dus L = -0,189v + 36,74
v = 127 geeft dan L = 12,7 km |
| |
|
| 18. |
v
= 90 geeft L = 19,88
v = 120 geeft 30% afname dus L = 0,7 • 19,88 = 13,916 km
v = 140 geeft 48% afname, dus L = 0,52 • 19,88 = 10,3376
De afname tussen 120 en 140 is van 13,916 naar 10,3376
Dat is een verschil van 3,5784 en dat is 3,5784/13,916 • 100% =
25,7% |
| |
|
| 19. |
001100110011000111000 dus
voor compressie zijn er 21 tekens
compressie geeft de rij 202120212021303130 en dat zijn 18 tekens
compressieratio = (21 - 18)/21 =
0,1428...
de compressie is voordelig want het aantal tekens na compressie is
kleiner dan het aantal voor compressie. |
| |
|
| 20. |
de
compressie is het kleinst als er na iedere teken wisseling is.
bijv. de rij 1010101010101... wordt 1110111011101110.... en
dat is dubbel zoveel tekens.
dus aantal na compressie = 2 • aantal voor compressie.
Stel dat er X tekens voor compressie zijn.
compressieratio = (X - 2X)/X =
-1 |
| |
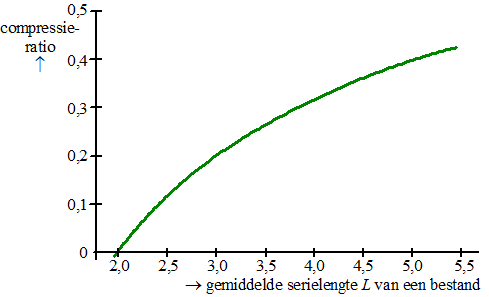
|
| 21. |
0,4 =
1 - 1,4709/L0,561
1,4709/L0,561 = 0,6
L0,561 = 1,4709/0,6 = 2,4515
L = 2,45151/0,561 = 4,95 |
| |
|
| 22. |
P(3 of
meer dezelfde tekens) = P(000... of 111....) = P(000....) +
P(111....)
= 0,83 + 0,23
= 0,52 |
| |
|