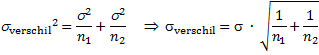|
||||||||||||||||||||||||||||||
| Als er twee gemiddelden gemeten worden. | ||||||||||||||||||||||||||||||
| Het komt natuurlijk
ook regelmatig voor dat je twee steekproven hebt gedaan en de gevonden
gemiddeldes daarvan met elkaar wilt vergelijken. Het probleem is
dan natuurlijk dat je ook twee standaarddeviaties hebt gemeten! Deze les zullen we bekijken wat je kunt zeggen over het verschil van twee gemeten gemiddeldes (μ1 - μ2). We maken wel de aanname dat beiden steekproeven komen uit normaal-verdeelde populaties en dat ze dus dezelfde standaarddeviatie hebben (dat er dus maar één "werkelijke'" standaarddeviatie op de achtergrond is). En verder moeten de metingen ook allemaal onafhankelijk van elkaar zijn. Als dat allemaal zo is, is de oplossing erg voor de hand liggend. Bereken gewoon de standaarddeviatie van alle metingen samen, alsof het één grote groep is. Dat geeft één σ. Voor het verschil van de twee gemiddelden geldt dan: |
||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||
| Het is deze
σverschil die we daarna gebruiken om het
betrouwbaarheidsinterval te berekenen, uiteraard met de t-verdeling
voor n1 + n2 metingen. Voorbeeld We kennen de Citoscores van 5 leerlingen van basisschool "de Liniaal" en de scores van 8 leerlingen van basisschool "Het Kompas". Die zijn als volgt: |
||||||||||||||||||||||||||||||
| • | De Liniaal: 520 - 534 - 546 - 531 - 542 | |||||||||||||||||||||||||||||
| • | Het Kompas: 534 - 539 - 543 - 541 - 526 - 530 - 548 - 532 | |||||||||||||||||||||||||||||
| Wat kunnen we zeggen
over het verschil in het gemiddelde van de twee scholen? De hele groep is 520 - 534 - 546 - 531 - 542 - 534 - 539 - 543 - 541 - 526 - 530 - 548 - 532 Die heeft gemiddelde een standaarddeviatie σ = 7,86 De gemiddeldes per school zijn μ1 = 534,6 en μ2 = 536,625 Bij 95%-betrouwbaarheidsinterval voor 13 metingen is t0,025 = 2,179 Het 95%-betrouwbaarheidsinterval is dan (536,625 - 534,6) ± 7,86 • √(1/5 + 1/8) Dat geeft [-2.45 , 6.51] Kortom: we kunnen er eigenlijk niet veel uit concluderen...... Als de metingen niet onafhankelijk van elkaar zijn. |
||||||||||||||||||||||||||||||
| Dat komt vaak voor
als je bijvoorbeeld resultaten VOOR en NA een bepaalde behandeling wilt
zien bij dezelfde proefgroep. We meten bijvoorbeeld de rekenscores van een groepje studenten in september, en daarna de rekenscores in december (na een aantal rekenlessen) van hetzelfde groepje nog een keer. In zo'n geval heb je allemaal "koppeltjes" metingen, namelijk per student de score in september en de score in december. Dat betekent dat je de formule voor σverschil hierboven niet mag gebruiken. In zo'n geval kun je het best een nieuwe lijst getallen maken die bestaat uit de verschillen per student. Bereken dus V = (score in december) - (score in september) voor elke student. Dat geeft een nieuwe rij getallen (V's). Die verschillen V beschouw je nu gewoon als één nieuwe steekproef, en daarvan kun je weer een 95%-betrouwbaarheidsinterval maken voor het gemiddelde. Voorbeeld. Van 8 studenten zijn de scores in september en in december gemeten en dat gaf: |
||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||
| Dat geeft de rij
verschillen: 10; 12; 19; 15; 1;
6; 0; -4 Daarvoor geldt μ = 7,57 en σ = 7,98 Voor een gemiddelde van 8 geldt dan σgemiddelde = 7,98/√8 = 2,82 De t-waarde bij het 95%-betrouwbaarheidsinterval en n = 8 is gelijk aan t0,025 = 2,365 Dat geeft interval 7,57 ± 2,365 • 2,82 = [0.90, 14.24] |
||||||||||||||||||||||||||||||
|
© h.hofstede (h.hofstede@hogeland.nl) |
||||||||||||||||||||||||||||||